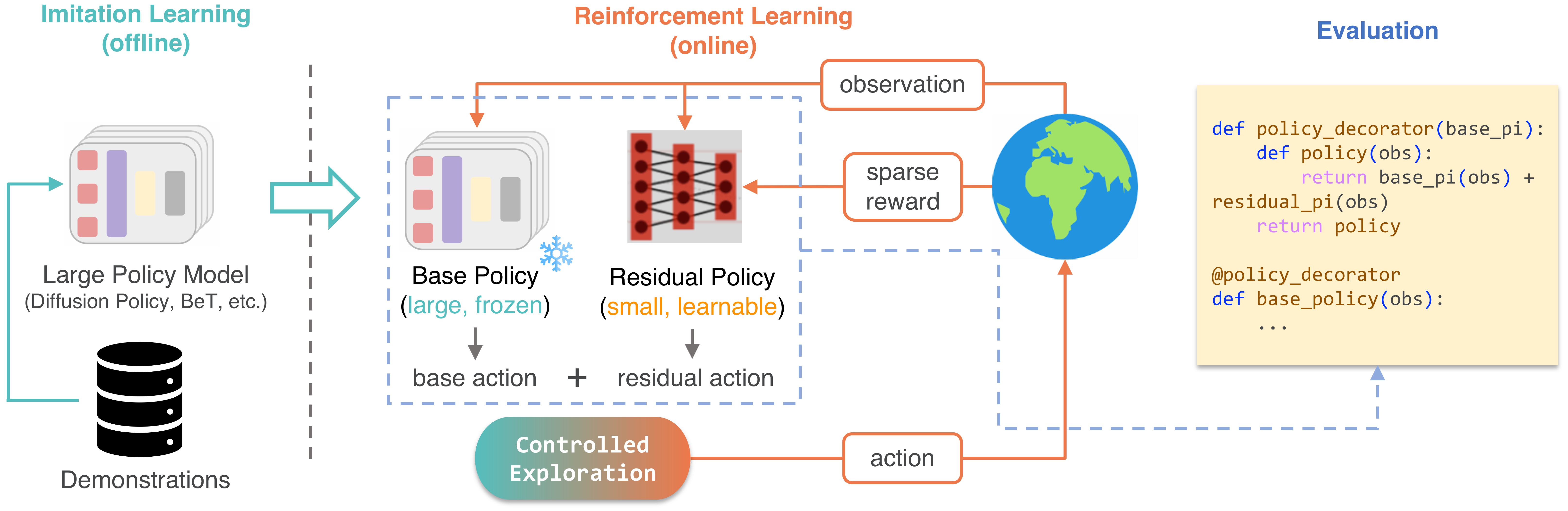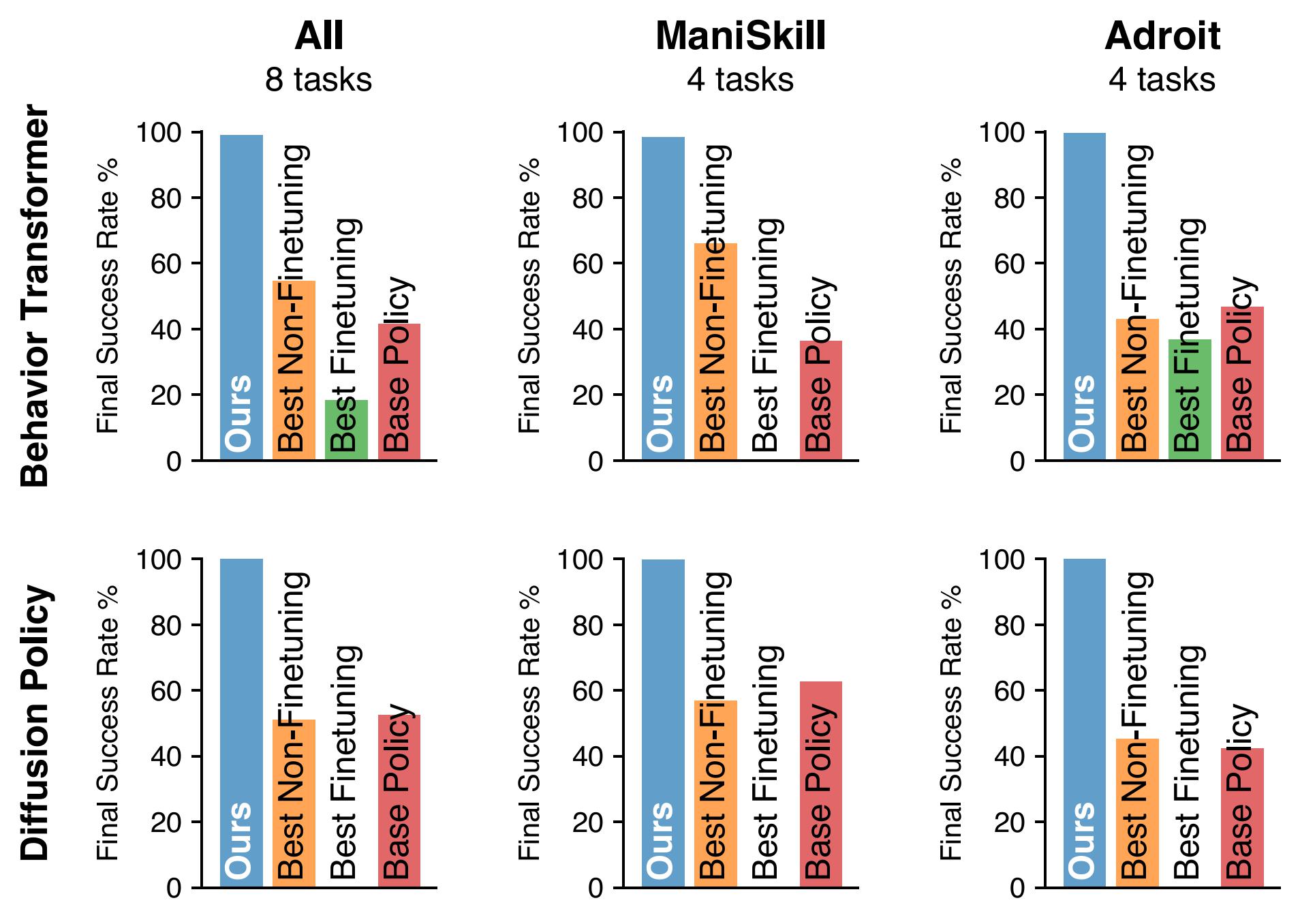
Improve Various SOTA Policy Models
Our framework, Policy Decorator, improves various state-of-the-art policy models, such as Behavior Transformer and Diffusion Policy, boosting their success rates to nearly 100% on challenging robotic tasks. It also significantly outperforms top-performing baselines from both finetuning and non-finetuning method families.